El puzle de los datos
Imaginad un puzzle, con cientos de piezas muy parecidas y cuyo número de piezas crece cada día.


Imaginad un puzle, con cientos de piezas muy parecidas, y cuyo número de piezas crece cada día. Como primera aproximación metafórica para acercarnos a entender el problema a escala humana puede valer el anterior ejemplo. La realidad a la que pretendemos acercarnos es que las piezas se cuentan en Zettabytes (1 ZB = 1021 bytes), cada segundo se genera miles de millones de nuevas piezas, y lo que tenemos delante no es un puzle de piezas homogéneas.
Construir el puzle de los datos es probablemente uno de los principales retos a los que se tiene que enfrentar nuestra generación. Con este artículo quiero hacer una aproximación a encuadrar el problema, enumerar las dificultades a las que nos enfrentamos y enumerar los recursos con los que contamos.
Aproximación teórica
Desde un punto de vista teórico es fácil definir el marco teórico del problema: los datos se generan y se ponen a disposición del gran público, luego se almacenan en plataformas que permiten el acceso, y por último se procesan. El proceso entra dentro del campo de estudio de la ciencia de datos, ¿qué hacer con tanta información? En esta área, el tradicional Big Data está abriendo paso al denominado Small Data, también conocido como Significant Data, o lo que es lo mismo: no es necesario usar todos los datos, hay que saber filtrarlos y siempre debe de prevalecer el sentido común. Con las conclusiones que saque la ciencia de los datos se actúa, abriendo así paso a la ingeniería de datos, caracterizada por la acción.
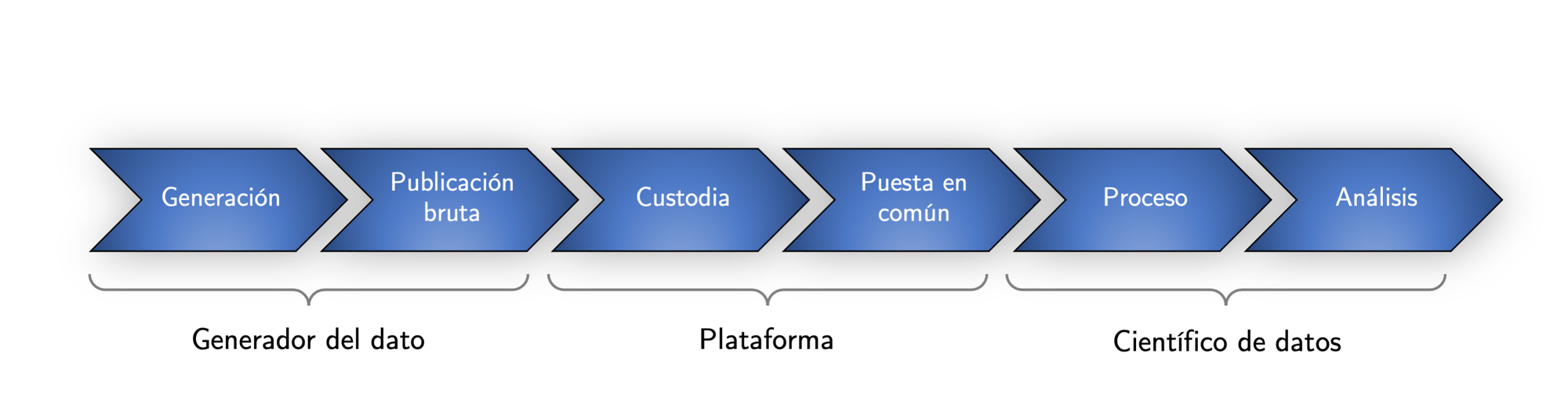
Considerando el anterior esquema, se va a descender a los diferentes problemas que aparecen en la práctica. La generación del dato crece a velocidad exponencial, al mismo tiempo que aumenta la complejidad de las infraestructuras. Adicionalmente, existe una gran heterogeneidad y desorden en el nivel de las plataformas, potenciado por el desigual desarrollo tecnológico y la creciente influencia de las grandes multinacionales. Por último, la ciencia de los datos se encuentra dando sus primeros pasos, lo cual provoca que todo esté todavía por descubrir.
Dificultades que tenemos
La consultora IDC calculó que la cantidad de datos que se generaron en 2016 fue de 16,1 ZB (1 ZB = 1021 bytes). Cuatro años después, el informe “Statista Digital Compass 2019” estimó los datos generados en 2020 en 47 ZB. En apenas cuatro años la cantidad de datos generados anualmente se ha multiplicado por más de tres. El mismo informe estima que para el 2030 la cantidad de datos anuales será de 612 ZB y en 2025 de 2.142 ZB. Unas cifras de locura, que nos hacen ver que en la actualidad solo estamos viendo la punta de un iceberg muy profundo. Para poner estas cifras en perspectiva, la revista Science en 2011 estimó que hasta el año 2003 en la historia de la humanidad se había creado una cantidad equivalente a 5 EB (1 Exabyte = 1018 bytes), estando sólo el 0,007% de esta información en formato papel. Desde entonces, cada año se ha sobrepasado con creces, y creciendo a un ritmo exponencial todo lo publicado en la historia de la humanidad hasta el año anterior.
Los anteriores informes estiman que en el año 2025 cada persona interactuará con dispositivos unas 4.800 veces al día, una interacción cada 18 segundos. El 25% del total de información que se cree será información en tiempo real, procediendo el 95% de esta información del IoT (Internet of Things – Internet de las cosas).
Para poder soportar toda esta avalancha de información ha habido que adaptar las infraestructuras. El sistema de direccionamiento IPv4 (32 bits), que admitía 232 (4.294.967.296) direcciones se reemplazó en el año 2016 por el IPv6 (128 bits) que admite 2128 direcciones (3,4 x 1038 direcciones) o la llegada del 5G que permite a los propios microprocesadores conectarse Internet permiten valorar la magnitud del fenómeno.
En este entorno de sobreabundancia informativa es absolutamente imprescindible ser capaz de diferenciar entre el ruido y el valor, para evitar caer en la parálisis por el análisis. Todo esto provoca que empiecen a aparecer problemas que hace unos años eran inimaginables: este es por ejemplo el caso de la latencia.
Para analizar los problemas asociados con la latencia hay que recordar la física del colegio. La velocidad de la luz en el vacío es de 300 km/ms (milisegundo). Por fibra óptica esta velocidad baja a los 200 km/ms. Si se considera que la información debe de ir al centro dónde se procesa y volver, es razonable considerar que por cada 100 kilómetros de distancia se consume 1 milisegundo de tiempo solo en desplazamiento. La proximidad es por tanto una variable clave, y así es como empezamos a hablar de la niebla (fog) en lugar de la nube (cloud). Para obtener ventaja de la proximidad, Tesla está estudiando alquilar la capacidad de proceso de datos de sus coches (edge computing).
El crecimiento exponencial de la cantidad de datos generados, la gran cantidad de datos que se generan en tiempo real, la adaptación de las infraestructuras o los nuevos requerimientos de respuesta prácticamente inmediata de los sistemas nos permite dibujar una primera aproximación de los problemas a los que nos enfrentamos al intentar ordenar las piezas del puzle.

Recursos con los que contamos
Con el objeto de poner orden en el anterior sistema es necesario destacar que ya hay mucho trabajo realizado. El primer nivel de organización es el derivado de la estandarización. Aquí destacan los esfuerzos realizados por IEEE, la ISO/IEC 20546:2019 o el trabajo realizado por la Unión Internacional de Telecomunicaciones (ITU). Todos los esfuerzos anteriores se materializan en el caso de España con el Esquema Nacional de Interoperabilidad.
Un segundo nivel es el legislativo. Los estándares indican las guías a seguir, la legislación obliga a seguir un determinado camino. En este sentido la Directiva (UE) 2019/1151 sobre herramientas y procesos digitales regula la interconexión entre los diferentes registros tanto oficiales como privados. Existe gran cantidad de legislación que obliga tanto a la administración pública como a las empresas a diferentes medidas en relación con digitalización e interconexión, pero aun así todavía queda mucho trabajo por hacer. La red SARA (Sistema de Aplicaciones y Redes para las Administraciones) es un excelente ejemplo de hacia dónde debemos de tender.
A nivel de plataformas sectoriales o privadas destacan la gran cantidad de consorcios y agrupaciones que se están creando durante los últimos años. La asociación de BlockChain Alastria, creada en Comillas, agrupa a más de 500 empresas españolas, todas con intereses en la digitalización y algunas de ellas con gran peso específico en la generación de datos. A nivel sectorial destacan los consorcios europeos del sector farmacéutico (Big Data for Better Outcomes), el marítimo o el vinícola entre otros varios. Muchos átomos separados que hay que empezar a combinar en diferentes moléculas.
Todo lo anterior está relacionado con la capa del uso de la información. Por debajo de esta capa de servicio se despliega una gran infraestructura. Autopistas y servicios de almacenamiento de la información. Reintel (Grupo REE) es el mayor proveedor de fibra oscura de España, gestionando una red de fibra óptica de más de 50.000 km de cables. Esta red, según se desarrolla en el punto siguiente está desplegada sobre la red de transporte del sistema eléctrico y la red ferroviaria. La fibra óptica representa las autopistas por las que viaja la información, no siendo casualidad que la energía a gran escala viaje por conductos paralelos a los conductos por los que viaja la información, todos ellos gestionados por REE.
Un segundo nivel al considerar la infraestructura son los sistemas de almacenamiento de datos. Desde un punto de vista del usuario caracterizado por la nube. Si consideramos la infraestructura estamos hablando de los grandes Centros de Proceso de Datos (CPDs). Los CPDs y su servicio son la gran commodity del siglo XXI. No todos los CPDs son iguales. Atendiendo a la calidad del servicio, los CPDs se clasifican en cuatro niveles TIER, destacando los CPDs TIER IV. Un CPD TIER IV debe de cumplir con una disponibilidad del 99.995% (interrupción del servicio de menos de 26 minutos al año), doble alimentación eléctrica independiente o redundancia en la mayor parte de sus sistemas, entre otras características.

Convergencia
Teniendo claro cual es el marco conceptual, los recursos con los que contamos y los principales problemas a los que nos enfrentamos estamos en condiciones de realizar una primera aproximación a la evolución en el futuro próximo de los datos, y a las mejores estrategias para generar valor con esta evolución. El denominador común de todos estos procesos es la convergencia. Convergencia entre tecnologías, entre energía e información, entre sectores y entre plataformas de datos entre otros factores.
Como se ha comentado, no es casualidad que Red Eléctrica de España, compañía que tiene el monopolio del transporte de energía en alta tensión, sea también el mayor propietario de fibra óptica del país. Tanto la energía como la información tienen naturaleza líquida. A nivel macroeconómico es una única empresa la propietaria de las tuberías por las que viaja el líquido. No es casualidad. Tampoco es casualidad que el Bitcoin sea básicamente un sistema que permite transformar energía en valor. Valor que una vez creado puede viajar en forma digital de unos agentes económicos a otros. La energía ni se crea ni se destruye, sólo se transforma, y viaja, aunque su almacenamiento históricamente ha planteado serias dificultades.
En nuestro sistema eléctrico de potencia la energía prácticamente no se puede almacenar: al mismo tiempo que se genera hay que consumirla. A pequeña escala, de forma descentralizada, sí que es posible el almacenamiento de la energía. Como la energía no se puede almacenar, hay que generar directamente lo que se consume. Por esto y por las economías de escala, la generación de energía se sitúa como un factor clave desde un punto de vista geopolítico. El gas de Omán o de Rusia, el petróleo o la energía nuclear provocan guerras y deciden gobiernos. Una primera conclusión, es que si somos capaces de generar y almacenar nuestra propia energía seremos un poquito más libres. Pues con los datos sucede exactamente lo mismo. Y esto es independiente de la escala.

¿Qué sucede con la generación y el almacenamiento de los datos? Internet y la fibra óptica parece que son el medio, y si no tenemos cuidado parece relativamente fácil la formación de monopolios naturales. Cada vez va a ser más difícil almacenar la enorme cantidad de datos que se van a crear en tiempo real. ¿No es el almacenamiento de datos otro factor estratégico como ya sucede con la propia generación de energía? ¿Tiene sentido que los grandes Centros de Proceso de Datos (CPDs) se encuentren fuera del territorio nacional? Es cuanto menos paradójica la respuesta a esta pregunta en contraste con la preocupación legislativa en relación con la protección del dato.
El caso de los vehículos eléctricos, como ya se adelantó al hablar de la latencia y el Edge Computing es un caso paradigmático de la convergencia entre el servicio al usuario, la gestión de la energía (un vehículo almacena y lleva energía de un sitio a otro) y la gestión de la información (los ordenadores de abordo, cuando el coche está parado están desocupados).
En este entorno de fuerte convergencia las tradicionales fronteras entre disciplinas desaparecen. ¿Quién programará un Smart Contract que se accione ante una entrada de datos determinada? ¿Un ingeniero, un economista o un abogado? Es indiferente la respuesta si pensamos en el mundo tradicional industrial, ya que no existe un requerimiento oficial asociado con titulación alguna. En el nuevo mundo digital se necesitará de un trabajo multidisciplinar entre profesionales dispuestos a compartir conocimientos y habilidades al mismo tiempo que disfrutamos construyendo el nuevo mundo.
Referencias
- Digital Economy Compass 2019. Statista. Enlace
- Reinsel, D., Gantz, J., Rydning, J. (2018). The digitization of the world from edge to core. International Data Corporation. Enlace
- Hilbert, M., & López, P. (2011). The world’s technological capacity to store, communicate, and compute information. Science, 332(6025), 60-65. Enlace
- Pérez-Chirinos, C. La tecnología tras las divisas virtuales: implicaciones a futuro. Enlace